Serverless for data scientists
2019-05-10This article is an edited version of a talk I gave at PyBay 2018. As such, it's loooong (sorry) and you may prefer to watch the video. The code examples are more complete at the accompanying GitHub repository.
If you’ve heard of serverless, you probably know it as a cloud architecture that minimizes the amount of long-lived infrastructure required by an application. In some situations this can reduce costs. That’s true, and relevant background, but this article will introduce you to its application in a new context: embarrassingly parallel function application and production machine learning.
If you’re a data scientist, you may not yet know much about serverless. This article will start off by introducing you to its most prominent use case: web operations. But as you’ll see, if you’re constrained by your computing resources, serverless is a lightweight alternative to setting up something like a Spark cluster (or waiting for someone else to set one up). It’s also a relatively easy way to throw a simple model into production, without support from ops.
The argument for serverless
Most data scientists aren’t interested in operations, but it’s a great context in which to demonstrate what makes serverless unusual, so bear with me.
It’s generally agreed that computers were a bad idea.

One of the wonderful things about the cloud is that the hardware is somebody else’s problem. You’re paying Amazon or Google or Microsoft to deal with it. They do a really good job, to the extent that you can largely forget about the hardware.
But moving to the cloud comes with costs. One of those costs is literal money. That’s partly because, despite the fact that we associate the cloud with the ability to scale dynamically, inevitably we end up paying for underutilized, long-lived resources.
And although the cloud successfully abstracts away the hardware, we still need to install, configure, secure, and maintain the operating system or database or whatever. This is a shame because for many of us it’s not what we want to do with our time. And for most of our employers, it’s not how they make money. They make money by deploying business logic.

So what if we could not only get rid of our physical infrastructure, but also the next layer up: the operating system or container? If we could do that then we could focus entirely on the business logic.
That is the goal of serverless.
What is serverless?
Consider a simple serverless deployment of an application that adds two numbers.
First, a request comes in to some kind of gateway service. In this case the
request is 2 + 2. In effect, the gateway service summons a machine out of
thin air (💥) and deploys the application on that machine. The new machine
figures out the response, sends it back, and then ceases to exist (💥).
Then another request (35 + 7) arrives, and the same thing happens: the gateway
creates a completely new machine (it doesn’t resurrect the machine used to
respond to the last instance), which performs the calculation and then ceases to
exist. Crucially, in the time between these two requests, the owner of this
adding application has no infrastructure.
More generally, you could say the amount of infrastructure scales almost linearly with utilization, and that linear relationship has an intercept of zero! (This is very important for understanding the situations in which serverless is cheap.)
This description captures what makes this approach unusual. It also elides and indeed mangles a bunch of engineering details that, as beginning users of serverless, we are largely able to ignore.
By the way, “serverless” is a really bad name, because you still have servers. In fact, you effectively have infinitely many of them. (In that sense, it’s a bit like “nonparametric statistics,” which is “nonparametric” in the sense that you have, well, lots of parameters, rather than in the usual sense of “non,” which is that that you have, well, none.)
Serverless deployment with AWS Lambda and Zappa
Generally, in order to derive the maximum benefits of serverless (i.e., making
the operations problems somebody else’s), you need to give money to one of the
big cloud providers to use its serverless platforms. Your options include AWS
Lambda, Google Cloud Functions, and Azure Functions. These services create,
destroy, and otherwise manage a very large pool of short-lived machines (like
the ones we used to calculate 2 + 2 and 35 + 7 above).
To demonstrate deployment on AWS Lambda, let’s use the example of a simple Python Flask application that tells the user the time:
# app.py
import datetime
from flask import Flask
app = Flask(__name__)
@app.route("/time")
def time():
return str(datetime.datetime.now())
if __name__ == "__main__":
app.run()
If you haven’t seen Flask before, there’s some boilerplate, but the important
thing is the time function (which returns the time) and the line immediately
before it, which is a decorator. That decorator tells Flask that if someone
visits the path /time, it should respond with the result of the function.
You can “deploy” this app locally by running python app.py:
$ python app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
And if you visit 127.0.0.1:5000/time you can get the time:
$ curl 127.0.0.1:5000/time
2019-05-09 21:09:46.450550
But if your laptop is firewalled sensibly and you have aspirations to occasionally put it to sleep, this is not a good place for this app to live in the long term. Let’s deploy it to AWS Lambda.
There’s a lot of fiddly bookkeeping involved in this, but the good news is you can avoid it all by using one of a number of command-line tools. I recommend Zappa. I like Zappa because it’s written in Python, and at least in principle it’s agnostic about which of the serverless platforms you deploy to. The other options I know about are the confusingly named Serverless and AWS’s Chalice.
Here’s how you use Zappa to deploy the time app. First you create and
activate a fresh virtual environment, and install your dependencies
into that virtualenv. In this case that’s Flask and Zappa. Copy
app.py from above into the same directory, then run zappa init:
python -m venv venv
source venv/bin/activate
pip install flask zappa
zappa init
zappa init will prompt you to answer a few questions. In this simple case you
can accept the defaults. That creates a configuration file that looks something
like this:
$ cat zappa_settings.json
{
"dev": {
"app_function": "app.app",
"aws_region": "us-east-1",
"profile_name": "default",
"project_name": "basic",
"runtime": "python3.6",
"s3_bucket": "zappa-ycr5dtiyk"
}
}
Then you do zappa deploy, and this is where Zappa shines:
$ zappa deploy
Calling deploy for stage dev..
Downloading and installing dependencies..
- sqlite==python36: Using precompiled lambda package
Packaging project as zip.
Uploading basic-dev-1534393616.zip (6.2MiB)..
100%|██████████████████████████████| 6.54M/6.54M [00:05<00:00, 902KB/s]
Scheduling..
Scheduled basic-dev-zappa-keep-warm-handler.keep_warm_callback with expression rate(4 minutes)!
Uploading basic-dev-template-1534393629.json (1.6KiB)..
100%|█████████████████████████████| 1.59K/1.59K [00:00<00:00, 3.29KB/s]
Waiting for stack basic-dev to create (this can take a bit)..
100%|███████████████████████████████████| 4/4 [00:09<00:00, 4.89s/res]
Deploying API Gateway..
Deployment complete!: https://ucyxlhvz7f.execute-api.us-east-1.amazonaws.com/dev
It’s taking care of a huge amount of fiddly stuff here. Most notably, it’s creating a zip file that contains both the application and its dependencies (as defined by what it finds installed in the virtual environment), and copying that to AWS. At the end of all the bookkeeping, you get a public URL you can use and share to replace localhost.
That URL no longer works (because I ran zappa undeploy), but trust me, it
used to do this:
$ curl https://ucyxlhvz7f.execute-api.us-east-1.amazonaws.com/dev/time
2019-05-10 04:30:59.270893
In broad strokes, this is what happens in response to the request for that URL:
- A computer is summoned out of thin air.
- The application and dependencies uploaded with Zappa are deployed to that new computer.
- The new computer receives the request.
- The response is computed and returned.
- The computer is destroyed.
This same thing happens every time someone visits the URL. (In practice, AWS does some caching of the instances to keep things responsive, but conceptually a fresh instance is created and promptly destroyed for each request.)
Crucially, this rather complicated procedure means that your app is in production, publicly accessible, and you’re paying exactly zero dollars for it while it’s not in use.
I’ve put all the code for this article in a GitHub
repository. In
there I also show how to upgrade this deployed application to allow the
time zone as a URL parameter. Zappa makes that upgrade easy (run zappa update), and offers a handy zappa tail command that consolidates the logs and errors
from the components of the deployed application in your laptop terminal. This
makes debugging easier if you screw up the deployment or the running application
generates an exception (say, if a user supplies an invalid URL parameter). You
can even use serverless in general (and Zappa with AWS Lambda in particular) to
configure cron jobs to run on serverless executors. For an example of that, see
my weather Twitter bot.
The advantages and limitations of serverless
Commonly cited advantages of serverless are that it allows you to focus on business logic, and you get infinite scalability built in at deployment. On the other hand, some would argue that serverless shares disadvantages with microservice architectures (e.g., complexity) and with cloud deployments (e.g., risk of vendor lock-in). The extent to which any individual engineer buys these claims varies, and they aren’t terribly relevant to the data science bit of this article (which I’m getting to!), so I won’t dwell on them.
One claimed benefit of serverless that is salient to the data science use case is cost: because we only pay when our code is running, and we pay in direct proportion to its usage with no unutilized overheads, it’s often cheap! For example, Postlight’s Readability API cost them about $10,000/month on EC2. They moved it over to AWS Lambda and now it costs $370/month.
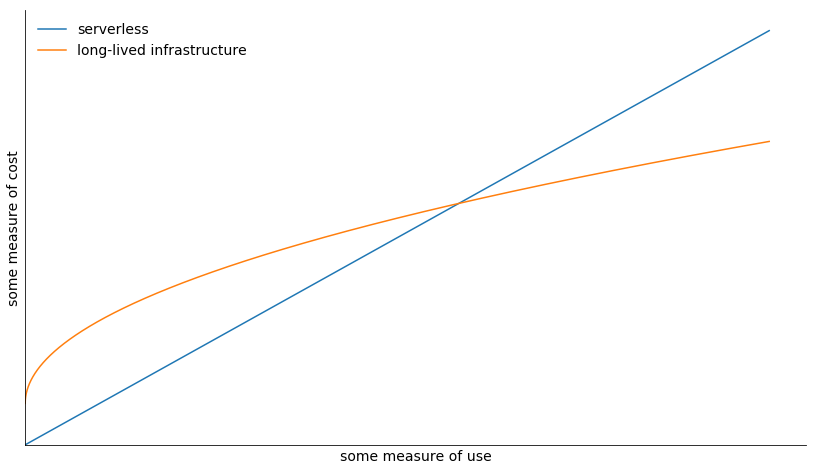
But it’s true to say serverless can be very expensive. Consider the (very schematic!) plot above. The cost of serverless scales linearly with utilization and has an intercept of zero. Generally, this is cheaper than the alternatives for small-scale deployments. And it may be cheaper for situations where compute usage is very bursty. But if you’re serving thousands of requests a second, you’re likely to be up in the region of the graph where the lines have long since crossed, and a non-serverless approach would be cheaper.
Perhaps the most fundamental difference between serverless and more traditional deployment patterns – and this is not so much a disadvantage as a set of restrictions inherent in serverless – is the nature of these machines that pop in and out of existence. I’ve been very vague about them so far. In part that’s because I’m honestly kind of sketchy about how they work. But let me tell you what I do know.

These are underpowered machines. In the case of AWS Lambda, at the time of writing, they have no more than 3 GB of RAM and a relatively small amount of local storage (75 GB). And they are living on borrowed time. Your function must complete in 15 minutes. Those limitations are kind of arbitrary, and they change rapidly (not long ago Lambda limited you to 1.5 GB, 500 MB, and 300 seconds!).
But the unavoidable restriction, which is inherent in the premise of serverless and will not change, is that these short-lived machines have no state. They have no record of previous instances. They even have no direct way of communicating with other running serverless instances. So, side effects like posting to Twitter or writing to a database aside, these serverless instances only support pure functions that take input and return a value. No global state.
Honestly, at this point you’re probably thinking: wow, serverless sounds terrible. Stick with me.
Mapping functions over arguments with AWS Lambda and Pywren
So! We’ve got these machines that:
- Have no internal state.
- Are not very fast.
But!
- We’ve got a lot of them
- And we only pay for them while we’re using them.
This raises interesting possibilities for data scientists! The rest of this article is about those possibilities, and a proof of concept tool called Pywren that was first described in “Occupy the Cloud: Distributed Computing for the 99%”. Even if you haven’t read a CS paper before (or for a while), I highly recommend that link (or the Morning Paper commentary).
Here’s a picture of data science to indicate that we’re moving into a new part of this article.

Pywren is a tool that maps functions across arguments using Lambda as the computational backend. What does “map functions across arguments” mean? In Python 2, simply this:
>>> def square(x):
... return x * x
>>> args = [1, 2, 3, 4, 5, 36]
>>> map(square, args)
[1, 4, 9, 16, 25, 36]
The map function takes another function (square in this case) and a list of
arguments to apply it to, and returns a list of the results of those
applications. In Python 3 this ends up being a bit more verbose because map
now evaluates lazily (i.e., returns a generator that you can consume immediately
or later). If this distinction is lost on you, don’t worry about it
(although do worry about the fact that Python 2 support will be ending at the end of
2019!)
map is probably familiar to you if you’re a JS or Haskell programmer (among
other languages). But if you’re a Python programmer, then you may not recognize
this function at all. The more Pythonic approach is a list
comprehension, which is superficially different, but fundamentally the same
idea:
>>> [square(x) for x in args]
[1, 4, 9, 16, 25, 36]
Pywren provides an (almost) drop-in replacement for Python’s built-in map
function that uses a separate AWS Lambda instance for each application of the
function to an argument, instead of your local machine. Here’s the syntax:
>>> import pywren
>>> pwex = pywren.default_executor()
>>> futures = pwex.map(square, args)
>>> futures
[<pywren.future.ResponseFuture at 0x11422ffd0>,
<pywren.future.ResponseFuture at 0x11422f588>,
<pywren.future.ResponseFuture at 0x11422f358>,
<pywren.future.ResponseFuture at 0x11422f748>,
<pywren.future.ResponseFuture at 0x10bbfff98>,
<pywren.future.ResponseFuture at 0x11422f470>]
>>> futures[0].result()
0
>>> [f.result() for f in futures]
[1, 4, 9, 16, 25, 36]
It’s not quite a drop-in replacement for map, because it returns a list of
futures objects rather than the results. But you can trivially get the
results from those futures.
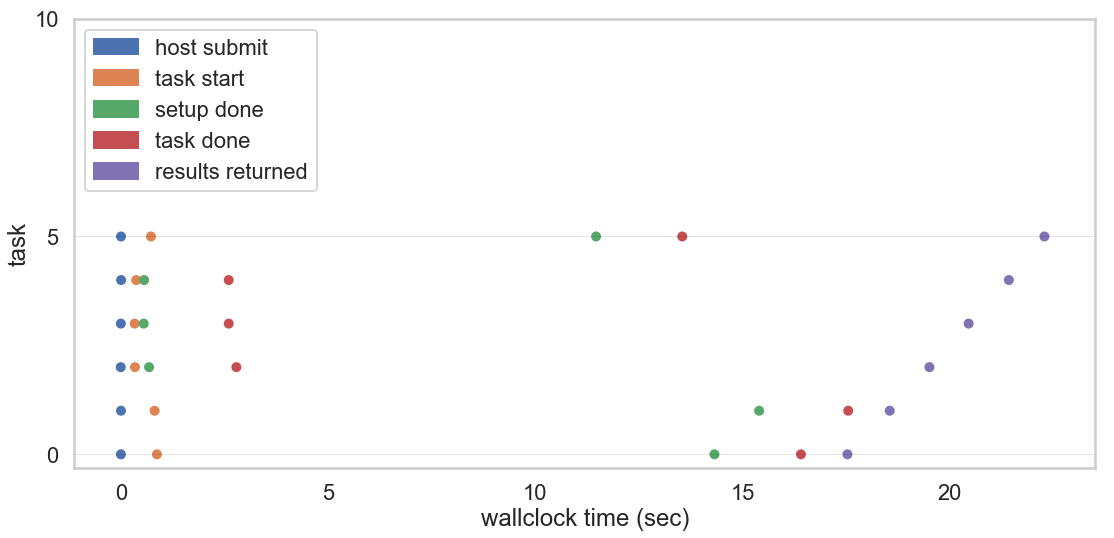
What’s actually going on when we use Pywren? Here’s my understanding:
- Pywren serializes the function and puts it on S3, and invokes the Lambdas (“host submit” in the graph above).
- The Lambdas start (that’s “task start”).
- They have to do some setup, which involves pulling and deserializing the job from S3 and installing an Anaconda Python runtime (that’s “setup done”).
- They compute the result and write it to S3 (“task done”), where it waits for
us to call the
resultmethod. - When we call that method, we download the result to our client (“result returned”).
Note, by the way, the scale on the x-axis here. Yes, we’re doing a bunch of stuff in parallel, but the overhead (around 20 seconds!) is enormous relative to the task. We’ll come back to this.
Embarrassingly parallel computation and carrots
The square function is a candidate for Pywren because it is
embarrassingly parallel. What does that mean?
Imagine a field of carrots. There are 8 rows, each containing 10 carrots. You have a harvester that can pick 1 carrot per second. It’s going to take 80 seconds to harvest the carrots.
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
What if you have 2 harvesters? They can work independently and harvest the carrots in half the time.
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕 🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
And if you have 8 harvesters, you can get the whole field done in 10 seconds.
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜 🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
You get a speedup in direct proportion to the number of workers because the tractors can work independently. This is not like co-authoring a book, where the two authors need to exchange information regularly about what they’ve done so far. The tractors are truly independent. There is no inter-worker communication. That’s embarrassingly parallel.
Anything in Python that you’d normally implement as a list comprehension
usually has this characteristic. Some for loops have side effects and are not
embarrassingly parallel, but if you can convert a for loop to a comprehension,
it’s likely embarrassingly parallel too.
Embarrassingly parallel Pywren examples
Now, squaring the first six numbers is cool, but what about some real work? Here are a few examples.
1. Web scraping
I wanted to scrape the abstracts for the many thousands of machine learning papers from a conference website. Doing this on my laptop took a long time because I was scraping them one at a time. I could have sped the process up by parallelizing the task across my CPU’s cores, but I would still have been constrained by the speed of my internet connection.
By shifting this map to Lambda with Pywren, I could work in parallel // RH: I was able to work in parallel? and also benefit from AWS’s faster internet connection! The code looks roughly like this:
>>> def scrape_batch(batch):
... for paper in batch:
... paper["abstract"] = scrape_abstract_for_one_paper(paper)
... return batch
>>> batches = [[paper1, paper2, ...], [paper101, paper201, ...], ...]
>>> pywren.get_all_results(pwex.map(scrape_batch, batches))
In this case I’m not mapping a function that scrapes one paper over a list of papers. Rather, I’m mapping a function that scrapes a batch of papers over a list of batches. I’m doing that because scraping one paper is relatively quick, which means that if I map them one at a time then the overhead of setting up Lambda instances dominates. By accumulating lots of pages until that 20-second overhead is worth it, I maximize my speedup.
The above is pseudocode. The full code (and the resulting dataset) is on GitHub if you’re interested.
2. The Black-Scholes equation
The Black-Scholes equation is a partial differential equation that describes the evolution of a stock option. Bradford Lynch wanted to solve it for many millions of configurations. Each solution is a pretty beefy numerical computation taking several tens of seconds. Without parallelization, the task would have taken 3 days on a single machine. On AWS Lambda using Pywren, it took 16 minutes.
3. Video encoding
Certain parts of video encoding algorithms are embarrassingly parallel because they’re performed one frame at a time. “Encoding, Fast and Slow: Low-Latency Video Processing Using Thousands of Tiny Threads” describes the application of an approach similar to Pywren’s to this problem.
This work is interesting because there’s a very significant speed threshold in video encoding: can you encode faster than 24 (or 60) frames per second? Beyond this, you’re in the realm of real-time video encoding, which opens up new kinds of use cases. It’s also interesting because, unlike Pywren, this approach doesn’t do a single Lambda submission for a single batch of tasks; the authors orchestrated a long-lived pipeline for ongoing video. Serverless for data engineering!
4. Hyperparameter optimization
In general, machine learning algorithms are a little tricky to parallelize. Distributed gradient descent, for example, is a famously subtle algorithmic problem, even before you get to the question of the system you’re distributing over.
But one part of the ML workflow that’s a good fit for Pywren out of the box is hyperparameter optimization.
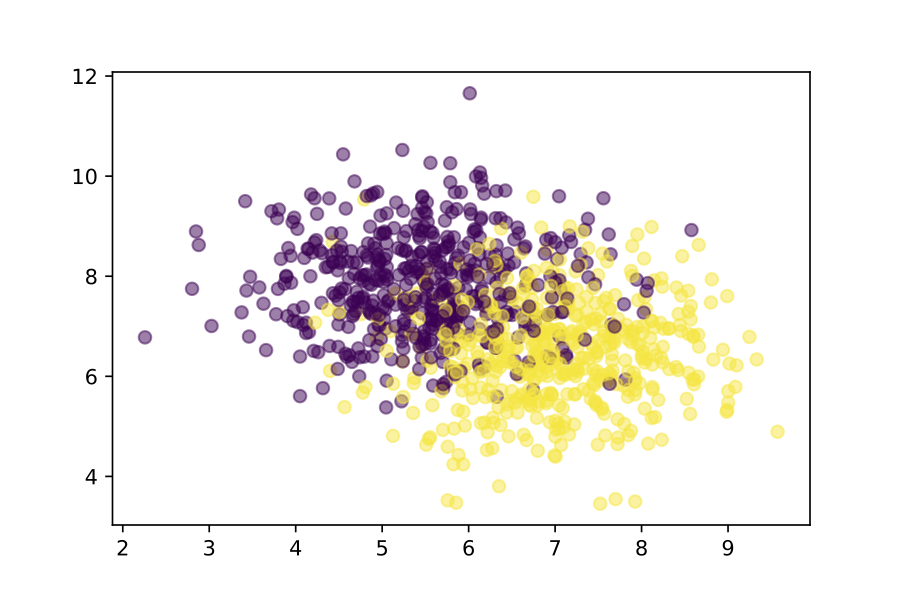
Suppose we have some training data, with two classes (yellow and purple)
and two features. We can train a model for this data locally using scikit-learn.
(This is a toy problem to illustrate the idea. Don’t get hung up on the sloppy
validation in this section; imagine a bigger problem!)
>>> from sklearn.neighbors import KNeighborsClassifier
>>> classifier = KNeighborsClassifier(n_neighbors=5)
>>> classifier.fit(Xtrain, ytrain)
>>> classifier.score(Xtest, ytest)
0.838
Here, n_neighbors is a “hyperparameter” – a magic number required by an ML
algorithm that you have to choose on a problem-by-problem basis. In this case,
we need to choose how many nearby training samples are going to get to vote on
the classification of our new point.
The usual way to do this is a simple search: we try all the possibilities, and
pick the one that gives the most accurate model. This is embarrassingly
parallel, so we can use Pywren! We need a list of the values of n_neighbors
we want to test and a function that returns a trained model to map over the
list:
>>> all_hyperparams
[{'n_neighbors': 1},
{'n_neighbors': 2},
{'n_neighbors': 3},
{'n_neighbors': 4},
{'n_neighbors': 5},
{'n_neighbors': 6},
{'n_neighbors': 7},
{'n_neighbors': 8}]
>>> def train_model(hyperparams):
... classifier = KNeighborsClassifier(**hyperparams)
... classifier.fit(Xtrain, ytrain)
... return classifier
Now we can send this computation off to AWS Lambda:
>>> futures = pwex.map(train_model, all_hyperparams)
>>> classifiers = pywren.get_all_results(futures)
>>> for hyperparams, classifier in zip(all_hyperparams, classifiers):
... print(hyperparams, classifier.score(Xtest, ytest))
{'n_neighbors': 1} 0.758
{'n_neighbors': 2} 0.782
{'n_neighbors': 3} 0.814
{'n_neighbors': 4} 0.82
{'n_neighbors': 5} 0.838
{'n_neighbors': 6} 0.838
{'n_neighbors': 7} 0.842
{'n_neighbors': 8} 0.828
Note that Pywren doesn’t only send back simple results like numbers. It can
send back a rich Python object with attributes and methods (in this case,
trained scikit-learn classifiers). This allows us to compute the accuracy of
each model using a local test set and choose the best one, all from the comfort of
our laptop.
Serverless for machine learning operations
Suppose we serialize the best model (n_neighbors = 7, apparently) and upload
it to a public S3 bucket. That allows us to do our final trick!
Remember Zappa, the CLI I demoed right at the start of this article that allows us to deploy Flask applications? If you use Zappa to deploy this Flask application, you’ve got machine learning in production!
url = "https://s3.amazonaws.com/modelservingdemo/classifier.pkl"
r = requests.get(url)
classifier = pickle.loads(r.content)
@app.route("/predict")
def predict():
X = [[float(request.args['feature_1']),
float(request.args['feature_2'])]]
label = classifier.predict(X)
if label == 0:
return "purple blob"
else:
return "yellow blob"
If you don’t believe me, visit the deployed application and change the URL parameters.
There is a whole startup based around the specific idea of putting machine learning into production using a serverless foundation in this way. I’m assuming their approach is somewhat more robust and complex than the dozen lines of Python above!
Some more limitations
Earlier we touched on some general engineering criticisms of serverless (complexity, lock-in, cost) and its limitations (no state, limited RAM and lifetime).
Before I conclude, I want to add to those lists in the specific context of data science.
First let’s address a couple of prosaic limitations to the specs of Lambda instances. If the individual function applications take longer than 900 seconds, AWS Lambda can’t help unless you break them into smaller atomic tasks. This can be tricky. And Lambda instances don’t have GPUs. This limits their utility for deep learning.
Second, let’s talk a little more deeply about algorithms. Pywren really only
works for embarrassingly parallel problems. Some MapReduce work is
embarrassingly parallel, but most has a shuffle step, where the results are
aggregated and manipulated and potentially distributed back out for further
work. The Pywren team and
others
have demonstrated workarounds that involve writing intermediate results to S3.
But at that point Pywren is no longer a drop-in replacement for the Python
map function. You need to think more carefully about the structure of the
algorithm you’re attempting to parallelize.
Luckily, in the case of linear algebra, the Pywren team have done some of that
work for us by releasing numpywren! This is
what it sounds like: a linear algebra library that is, from the point of view
of the user, very similar to numpy. On the backend it uses AWS Lambda to
perform the computations, but it goes beyond Pywren by handling the orchestration
and communication required to apply the fastest algorithms to linear algebra on
serverless.
Conclusion
So, you’ve seen that serverless is good for deploying websites and running cron jobs. And you saw at length that it’s good for a certain kind of computation, namely embarrassingly parallel stuff. You can even imagine a workflow that combines these ideas: running hyperparameter optimization on AWS Lambda using Pywren, and then deploying the best model to AWS Lambda using Zappa. Serverless is good for these things in the sense that it’s relatively easy to set up and cheap to use.
The reason it’s cheap (and the high-level principle to take away from this article) is what those applications have in common: they’re bursty. They sometimes require significant resources that Lambda can scale up to accommodate, but they sometimes require zero or almost zero resources. Your web product is new, your cron job isn’t on, or you’re working interactively and you’re now staring at your notebook trying to figure out what the results mean. On serverless, you’re not paying for that time.
So: the best thing about serverless is not so much that it’s great when you’re using it (although the ability to scale up is powerful), but that it’s great when you’re not using it!
AWS is not about paying for what you use, it's about paying for what you forgot to turn off.
— Deadprogrammer (@deadprogrammer) April 24, 2019
Remember the Pywren paper was called “Distributed Computing for the 99%”? The data science 1% operate in organizations that do data science at a scale where they always require some (if not most) of their computing resources. Global consumption varies, but it doesn’t go down to zero. Or if it does, peak usage is so high that’s it’s cheaper to just buy the dang cluster. And the data scientists have data engineering, tools and operations support to take care of those long-lived resources. Serverless in the sense described in this article is not for those data scientists.
But if you’re operating independently, and you don’t have the money, the engineering support, or the patience for heavyweight solutions, take a look at zappa, pywren and the serverless ecosystem.
Thank you for coming to my TED talk.